
前言
ImageNet 每年舉辦競賽(ILSVRC),歷屆比賽的模型演進非常精彩,簡單敘述如下:
1. 2012年冠軍 AlexNet 錯誤率比前一年減少超過10%,且首度引用 Dropout 層。
2. 2014年亞軍 VGGNet 承襲 AlexNet 思路,建立更多層的模型,達到 16及19 個隱藏層。
3. 2014年圖像分類冠軍 GoogNet & Inception 同時使用多種不同大小的Kernel,讓系統決定最佳的Kernel。
4. 2015年冠軍 ResNets 發現 20 層以上的模型前面幾層會發生優化退化(degradation)的狀況,因而提出以『殘差』(Residual)解決問題。
Keras把它們都收錄進框架內,稱為Keras Applications ,包括下列幾項:
1. Xception
2. VGG16
3. VGG19
4. ResNet50
5. InceptionV3
6. InceptionResNetV2
7. MobileNet
除了Xception及MobilNet,其它都相容於TensorFlow。這些模型的層數都相當多,且使用大量資料訓練。若使用一般的電腦會等到天慌地老。所以Keras將這個團隊的模型儲存起來,我們不需訓練直接拉進來就可以套用了。
VGG
VGG(Visual Geometry Group) 是由牛津大學計算機視覺組所提出的模型。VGG模型用於圖像的分類(Image Classification)。
什麼是圖像分類呢? 以MNIST為例,先用 60000 張已知種類的圖片進行訓練,然後再辨識新的未知圖片是屬於 10 種之中的那一類,這叫圖像分類。所以VGG的用途與 MNIST 同性質。不過 VGG 它可以辨識 1000 個種類,比如貓啦,狗啦,老虎啦。
VGG 屬於圖像分類,是把整張圖片歸屬於那一個種類的模型,所以沒有標識圖片位置(座標)的功能。這跟物件偵測是不一樣的。物件偵測是可以標識物件位於圖片的那一個位置。所以使用VGG偵測未知圖片時,未知圖片只能有單一個物件,而且背景盡可能單純一點。
VGGNet 是在更細的粒度上實現的AlexNet。AlexNet採用 7*7的卷積核,而VGGNet則使用3*3 的卷積核架構去實現更深層次的卷積網路神經網路。目前已證實增加卷積神經網路的深度,增加更多的隱藏層和權重可以明顯的改進識別程度。 從VGGNet的結構而言,與AlexNet並沒有太大的區別,但因增加了更多的隱藏層,參數調整範圍更大,所以最終生成的模型參數是AlexNet的3倍左右
VGG 使用100萬張圖片訓練,再分類成1000種。此模型已成為通用解決方案了。若圖片不屬於這1000種,可以將Input卷積層換掉,只利用中間層取得特徵,稱為Transfer Learning。VGG有二個版本,分為VGG16(13個卷積層及3個全連接層) 與VGG19(16卷積層及3個全連接層)
VGG16的結構如下
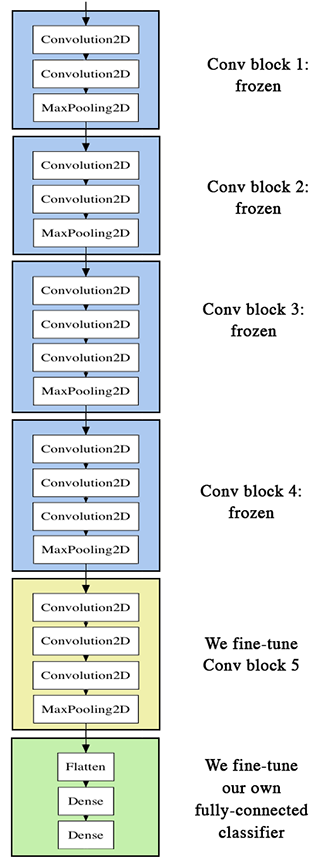
若要手動建立模型,如下
from keras.models import Sequential
from keras.layers import Dense, Activation, Dropout, Flatten
from keras.layers import Conv2D
from keras.layers import MaxPooling2D
input_shape = (224, 224, 3)
model = Sequential([
Conv2D(64, (3, 3), input_shape=input_shape, padding='same',
activation='relu'),
Conv2D(64, (3, 3), activation='relu', padding='same'),
MaxPooling2D(pool_size=(2, 2), strides=(2, 2)),
Conv2D(128, (3, 3), activation='relu', padding='same'),
Conv2D(128, (3, 3), activation='relu', padding='same',),
MaxPooling2D(pool_size=(2, 2), strides=(2, 2)),
Conv2D(256, (3, 3), activation='relu', padding='same',),
Conv2D(256, (3, 3), activation='relu', padding='same',),
Conv2D(256, (3, 3), activation='relu', padding='same',),
MaxPooling2D(pool_size=(2, 2), strides=(2, 2)),
Conv2D(512, (3, 3), activation='relu', padding='same',),
Conv2D(512, (3, 3), activation='relu', padding='same',),
Conv2D(512, (3, 3), activation='relu', padding='same',),
MaxPooling2D(pool_size=(2, 2), strides=(2, 2)),
Conv2D(512, (3, 3), activation='relu', padding='same',),
Conv2D(512, (3, 3), activation='relu', padding='same',),
Conv2D(512, (3, 3), activation='relu', padding='same',),
MaxPooling2D(pool_size=(2, 2), strides=(2, 2)),
Flatten(),
Dense(4096, activation='relu'),
Dense(4096, activation='relu'),
Dense(1000, activation='softmax')
])
model.summary()
使用VGG16已訓練好的模型
底下代碼,使用VGG16模型,此模型的開發團隊已使用高效電腦訓練好資料,我們只需將圖片傳入,就可以輸出圖片裏的圖案是屬於那一類的,就連它的原理都不用管了。
使用前需pip install tensorflow Pillow。
另外請注意,在 import tensorflow as tf 之後,才能 import keras。否則會出現 keras.application屬性找不到的錯誤。
第一次執行,會將模型下載到c:\<user>\.keras\models,其中的vgg16_weights_tf_dim_ordering_tf_kernels.h5為權重,有500M以上,所以需等待一下。若下載發生錯誤,需手動將.keras刪除重下。
第二次偵測時,因為不用從網路下載模型,也不用訓練,所以速度會比較快。
如果使用 GPU 計算,且 GPU 的 Ram 有12G的話(RTX 3080Ti),可以正常執行。但如果 GPU 的 Ram 只有 4G 的話,會因為記憶体不足而發生
Failed to get convolution algorithm. This is probably because cuDNN failed to initialize 例外,
所以需加入如下設定
#因GPU記憶体不足而發生例外,請加入如下設定
tf.config.experimental.set_memory_growth(gpus[0], True)
tf.keras.applications.VGG16(weights=’imagenet’, include_top=True) 會載入模型。
include_top=True 表示會載入完整的 VGG16 模型,包括加在最後3層的卷積層
include_top=False 表示會載入 VGG16 的模型,不包括加在最後3層的卷積層,通常是取得 Features
tf.keras.preprocessing.image 套件中的 load_img() 可以載入RGB格式的圖片,然後用 img_to_array() 轉成 numpy 陣列,就可以開始偵測。如果習慣使用cv2的話,可以用 cv2 讀檔,縮圖,記得還要轉成 RGB格式,否則會偵測錯誤。
讀取圖檔後,要在最前面維度新增一個空的維度,用來存放偵測後的權重
#最前面新增一個維度,用來儲存權重
x = np.expand_dims(img, axis = 0)
最後使用 model.predict(x) 開始偵測圖片。偵測圖片前,需先將圖片縮放到224*224的大小才可偵測
import cv2 import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2' import tensorflow as tf import keras#需置於tf之後 import numpy as np from PIL import Image, ImageFont, ImageDraw #限定使用GPU #gpus = tf.config.experimental.list_physical_devices(device_type='GPU') #tf.config.experimental.set_visible_devices(devices=gpus[0], device_type='GPU') #GPU 的Ram如果只有4G,會出現錯誤,所以要加如下設定 #tf.config.experimental.set_memory_growth(gpus[0], True) #限定使用 CPU cpus = tf.config.experimental.list_physical_devices(device_type='CPU') tf.config.experimental.set_visible_devices (devices=cpus) # include_top=True,表示會載入完整的 VGG16 模型,包括加在最後3層的卷積層 # include_top=False,表示會載入 VGG16 的模型,不包括加在最後3層的卷積層,通常是取得 Features model = keras.applications.VGG16(weights='imagenet', include_top=True) # 處理要辨識的影像 #使用tf讀取圖檔 #img = keras.preprocessing.image.load_img('chicken.jpg', target_size=(224, 224)) #x = keras.preprocessing.image.img_to_array(img) #使用OpenCv讀取圖檔 img = cv2.imdecode(np.fromfile('../tiger.jpg', dtype=np.uint8), cv2.IMREAD_UNCHANGED) img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img_224 = cv2.resize(img, (224,224), interpolation=cv2.INTER_LINEAR) #影像需於最前面新增一維度,用來儲存偵測後的權重 x = np.expand_dims(img_224, axis=0) x = tf.keras.applications.vgg16.preprocess_input(x) # 預測,取得features,維度為 (1,7,7,512) features = model.predict(x) print(model.summary()) # 取得前三個最可能的類別及機率 results=keras.applications.vgg16.decode_predictions(features, top=3)
result=results[0][0] print('Predicted:', result) #寫入文字並顯圖 pil = Image.fromarray(img) font = ImageFont.truetype('simsun.ttc', 100) txt=f'名稱 : {result[1]}\n信心度 : {result[2]*100:.2f}%' ImageDraw.Draw(pil).text((5, 5), txt, font=font, fill=(255,255,0)) img=cv2.cvtColor(np.asarray(pil), cv2.COLOR_RGB2BGR)
img=cv2.resize(img, (1024, 768), interpolation=cv2.INTER_LINEAR) cv2.imshow('test', img) cv2.waitKey(0) 結果: Model: "vgg16" _________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 224, 224, 3)] 0 _________________________________________________________________ block1_conv1 (Conv2D) (None, 224, 224, 64) 1792
_________________________________________________________________
block1_conv2 (Conv2D) (None, 224, 224, 64) 36928
_________________________________________________________________
block1_pool (MaxPooling2D) (None, 112, 112, 64) 0
_________________________________________________________________
block2_conv1 (Conv2D) (None, 112, 112, 128) 73856
_________________________________________________________________
block2_conv2 (Conv2D) (None, 112, 112, 128) 147584
_________________________________________________________________
block2_pool (MaxPooling2D) (None, 56, 56, 128) 0
_________________________________________________________________
block3_conv1 (Conv2D) (None, 56, 56, 256) 295168
_________________________________________________________________
block3_conv2 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_conv3 (Conv2D) (None, 56, 56, 256) 590080
_________________________________________________________________
block3_pool (MaxPooling2D) (None, 28, 28, 256) 0
_________________________________________________________________
block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160
_________________________________________________________________
block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808
_________________________________________________________________
block4_pool (MaxPooling2D) (None, 14, 14, 512) 0
_________________________________________________________________
block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808
_________________________________________________________________
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
_________________________________________________________________
flatten (Flatten) (None, 25088) 0
_________________________________________________________________
fc1 (Dense) (None, 4096) 102764544
_________________________________________________________________
fc2 (Dense) (None, 4096) 16781312
_________________________________________________________________
predictions (Dense) (None, 1000) 4097000
=================================================================
Total params: 138,357,544
Trainable params: 138,357,544
Non-trainable params: 0
_________________________________________________________________
None
Predicted: [('n01514859', 'hen', 0.95593417), ('n01514668', 'cock', 0.03969067), ('n01807496', 'partridge', 0.0023021759)]
