
DeepFake 深度偽裝,是一種變臉的演算法,常見的有
DeepFaceLab : 專業複雜,訓練久。
FaceFusion : 幾張圖置換整個影片,快速且效果好。
FaceSwap : A 影片置換到 B影片,訓練久。
FaceFusion
faceFusion 運作原理
FaceFusion 只使用一張或多張圖,就將整個影片的人臉全部換掉,速度快且效果好。
- 使用類似 InsightFace / ONNX Runtime embedding 技術。
- 單張臉 → 轉換成「特徵向量(embedding)」。
- 多張臉可提升特徵向量的泛化程度。
- 可以泛化到不同角度、光線、表情。
git for Windows
後面需要使用 git 下載 FaceFusion 的程式碼,請先到 https://git-scm.com/install/windows 下載 Git for Windows/x64 Setup.
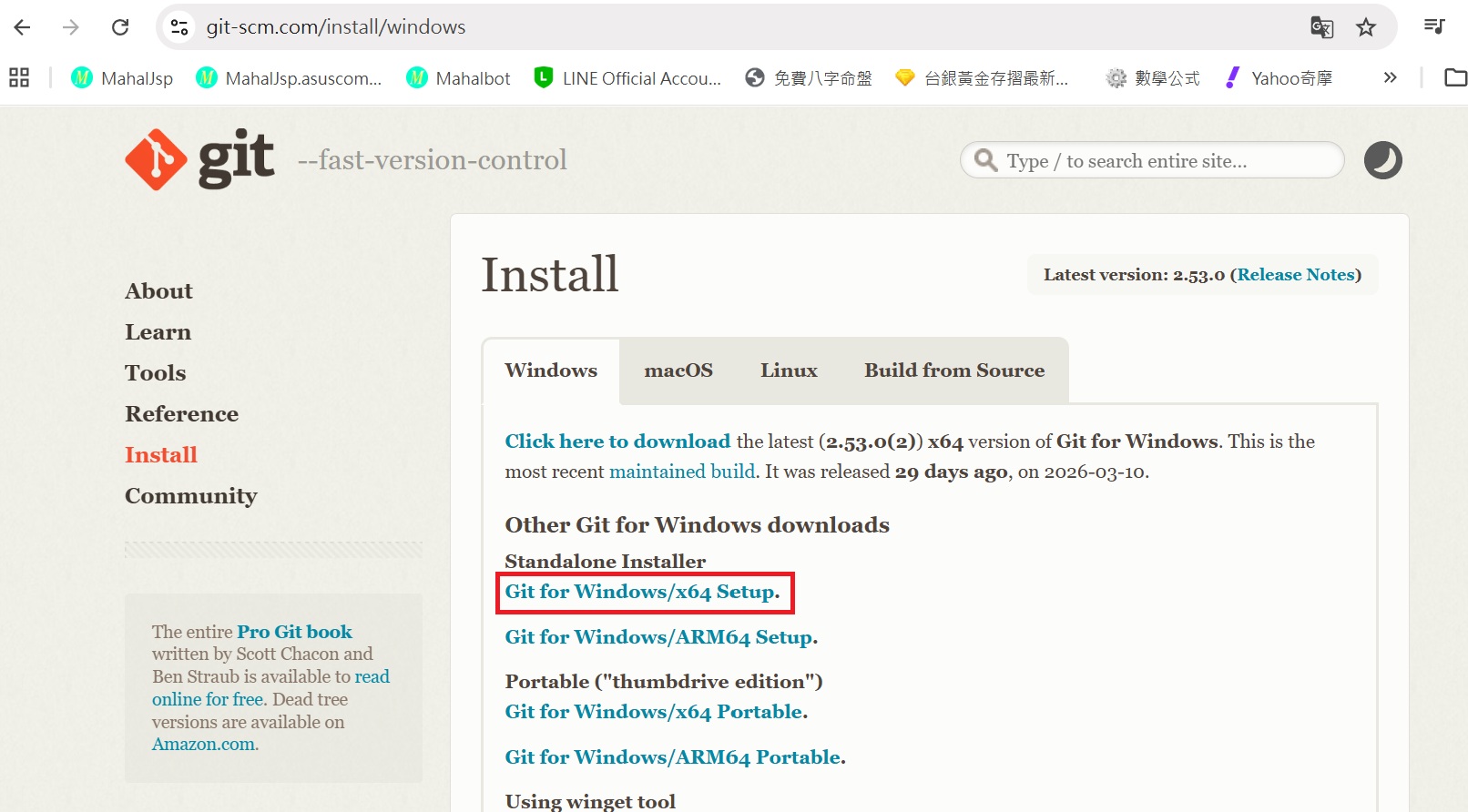
安裝時,請將 vim 改成 notepad++。
安裝 ffmpeg
請到 https://ffmpeg.org/download.html,選取 Windows builds by BtbN,記解壓縮將目錄改成 ffmpeg,然後移到 C:\,系統 path 要加上 c:\ffmpeg\bin。
安裝 Cuda
facefusion 目前只支援使用 Cuda 12.9 及 cudnn,若是安裝 Cuda 13,會出現 cublasLt64_12.dll 及 cudnn64_9.dll 找不到的錯誤。請到如下網址下載 cuda 及 cudnn。
安裝完記在系統 path 新增 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.9\bin。
Cuda 12.9 下載網址如下
https://developer.nvidia.com/cuda-12-9-1-download-archive?target_os=Windows&target_arch=x86_64&target_version=11&target_type=exe_local https://developer.download.nvidia.com/compute/cudnn/redist/cudnn/windows-x86_64/
FaceFusion 專案設定
進入 DOS 視窗使用如下指令下載 facefusion 原始碼
e: mkdir python cd python git clone https://github.com/facefusion/facefusion.git
使用 notepad++ 開啟專案下的 requirements.txtt 檔案,更改如下設定(後續才可啟動 GPU)
#onnxruntime==1.24.3
onnxruntime-gpu==1.24.3
然後執行如下指令安裝相關套件
cd facefusion python -m venv .venv .\.venv\Scripts\activate pip install -r requirements.txt
影片下載
想下載 Youtube 影片,可安裝本人撰寫的 MahalYT app。此 app 使用 C# 開發,可下載 Youtube mp3/mp4,而且完全沒有 Youtube 置入的廣告。
使用 MahalYT 下載的影片,就算畫質是 1920*1080,最好使用如下指令讓影片重新刷新一次,不然在 facefusion 可能會被解析成 640*360 的解析度。
另需特別注意一點,FaceFusion 只會找影片第一偵的人臉 512 特徵向量。所以如果影片的第一偵沒有人臉就會失敗而無法轉換。所以請在 DOS 命令視窗執行如下指令 Render 影片。
#軟体編碼 ffmpeg -ss 00:00:05 -i ctv.mp4 -vf scale=1920:1080 ctv_1.mp4 #硬体編碼 ffmpeg -ss 00:00:05 -hwaccel cuda -i ctv.mp4 -vf "hwupload_cuda,scale_cuda=1920:1080" -c:v h264_nvenc ctv_1.mp4
指令的開頭加入 -ss xx:xx:xx,-ss 指定人臉開始出現的位置,也就是要開始擷取影片的位置。在其後面也可加入 -to xx:xx:xx 指示要擷取最後影格的位置。
測試素材
不想自行收集影片的人,可由本人提供的素材進行測試。
下載 face.zip,然後將 face 目錄置於專案下之。
下方素才最左邊影片為原始影片(1920*1080),中間為轉換後的影片,右邊則為換臉後的影片。
| 原始影片 | 轉換後影片 | 換臉影片 |
請下載左邊的原始影片,然後將原始影片置於 facefusion 專案目錄中。
執行 facefusion
第一次執行 run 會下載相對應的模型,並置於 facefusion\.assets\models 之下
python facefusion.py run
結果:
* Running on local URL: http://127.0.0.1:7860
* To create a public link, set `share=True` in `launch()`.
然後在瀏覽器輸入 http://localhost:7860
指令訓練
使用 headless-run 開始訓練,注意 –output_path 一定要指定目錄,這是個很奇怪的設計。
python facefusion.py headless-run --source-paths ./face/1.jpg ./face/2.jpg ./face/3.jpg ./face/4.jpg ./face/5.jpg --target-path b_1.mp4 --output-path ./output_b.mp4
FaceSwap
FaceSwap 要由 A 影片的人臉置換到 B 影片,訓練過程非常久,三分鐘影片約要 72 小時。
FaceSwap 屬開源程式碼,由 Python 調用 tkinter 視窗套件寫成,然後包裝成 .exe檔。
網路上說其逼真程度沒有任何人可以用肉眼辨別其真假。其實這只是唬爛的而以,要分辨其實還蠻容易的。比如辨識耳朵旁的眼鏡框,一會有、一會沒有,尤其是臉旁的頭髮,都是 faceswap 無法解決的問題。不過如果 A/B 兩影片選的好,還真的不易辨識真偽。
要置換影片中的人臉,當然是需要先下載二段影片,一段是原始影片(A),另一段是要置換的人臉影片(B),也就是說,把B影片中的人臉換到 A影片中。
A影片 : 待換影片 : Original
B影片 : 人臉素材 : Swap
A 影片裏的人臉等待著被更換成新人臉。那麼新的人臉在那兒呢? 全部由 B影片提供,所以我們稱 B 影片為 “素材影片”。
要製作讓人不太容易辨識的技巧:
1. 選擇不要有頭髮蓋住臉部或瀏海的影片。
2. 不要選擇有載眼鏡的人臉。
完成品展示
底下是本人訓練完成的成品展示。
| 原始影片-蔡尚樺 | fake影片-南韓主播 |
| 原始影片-潘照文 | fake影片-南韓主播 |
示範資料下載
底下是本專案所使用的原始資料,沒有顯卡的人可下載進行測試
第一組測試資料 : deepfake1.zip
第二組測試資料 : deepfake2.zip
Faceswap 步驟
Faceswap負責將影片中的人臉抽出,訓練,置換。這支程式是由 Python 去調用 tkinter 所寫成的,所以畫面蠻醜的,不過能用就好。
下載安裝
先到 https://github.com/deepfakes/faceswap/releases 下載 faceswap_setup_x64.exe
安裝時,請勾選 Setup for NVIDIA GPU。安裝後主程式的路徑在 C:\Users\登入者\faceswap目錄中。安裝時,會自動下載 miniconda及其他套件,所以需要花費一段蠻久的時間
抽取人臉
將 A, B二段影片的人臉抽取出來(Extract)
首先選取 Extract功能,Input Dir 選取影片,Output Dir 選取抽出人臉後要存放的位置,
比如 VideoA\images 及 VideoB\images,然後按下Extract按鈕。
請注意,B 影片是人臉更換的素材,所以 B 影片的長度最好比 A 影片長,這樣就可以抽到更多的人臉素材。當要置換到 A 影片時就可以有更多的選擇,會讓置換後的影片更加完美。

訓練
切換到 Train分頁,Input A/Input B分別選取 videoA\images及 videoB\images目錄。
Model Dir 是將來訓練完成後模型要儲存的地方,在專案下新增一個空白的目錄 models 即可。

然後往下拉,會看到 Timelapse Input A/B,也是一樣選取 videoA\images及 videoB\images,Timelapse Output則在專案下建立一個空白目錄 output即可。

最後按下 Train 開始進行訓練,這個過程會花費相當久的時間。
以nVidia RTX3080Ti 顯卡,二分鐘1080p 的影片,訓練時間大概要花了115小時,所以請耐心等候。
匯出影片
接下來就要匯出影片了,匯出影片只需原來的 A 影片(video_A.mp4),videoA_alignments.fsa檔案,及 models 目錄。不需要 B 影片,也不需要任何抽取出的人臉圖片,因為這些資料都在 models 裏面。
請選擇 Convert 分頁
Input Dir 選擇 A 影片,
Output Dir 選擇要匯出的目錄 : fakeout
Alignments 選取 VideoA 裏的 .fsa 檔
Model Dir 選取模型目錄 models。
Plugins 選擇 Match-Hist,
Writer選擇 Ffmpeg,
然後按下Convert按鈕。此動作蠻快的,幾秒鐘就完成。

開啟 fakeout 目錄,就可以看到匯出的影片了。
影片下載
YouTube 是尋找影片的最佳網址,但要如何下載 Youtube 影片呢 ? 請先到官網 ytdlp (YouTube DownLoad P-brench)下載 ytdlp-interface.zip,解開後執行 ytdlp-interface.exe 即可進行下載。官網文件說明,就算不是 Youtube 的影片也可下載。經本人確認, FaceBook 影片也沒問題。
ypdlp官網原文說明如下:
This is a Windows graphical interface for yt-dlp, that is designed as a simple YouTube
downloader. Since v1.2, the interface also accepts non-YouTube URLs, so theoretically it
can be used to download from any site that yt-dlp supports (see the list).
請將下載好的 A, B影片,分別放在 VideoA及VideoB目錄中。
線上下載
亦可到 https://y2mate.tools/en57b5/youtube-mp4 將youtube的影片網址貼上,即可進行下載。
影片切割
影片切割,可以使用 格式工廠 處理,或者使用 https://www.pkstep.com/archives/27067