
yolo (You only look once) 與 Google Object Detection 一樣,同屬 SSD (Single Shot MultiBox Detector 單鏡頭多盒檢視器),但比 GOD 快速精準,而且訓練時間也少很多。
yolo 原由 Joseph Redmon 開發,但 Joseph 發現 yolo 其實是個超極恐怖的東西,可以運用在軍事武器的 AI 殺戮,所以宣佈不再開發,然後由台灣與俄羅斯學者共同接手。但中國近年來積極開發 v5 版本,最後演變成 v7 版本,經測試的確快又準,所以官網才把 v7 變成 offical (官方) 版本。
yolo 自 v5.0 後,已全面改用 PyTorch 架構,捨棄 darknet。PyTorch, TensorFlow 或是 darknet 都是機器深度學習框架。darknet 已經跟不上時代潮流,這也是 yolov5 要改框架的原因。
Python套件
要執行 v7 版,需安裝如下套件
官網要求的版本
pip install tqdm requests matplotlib scipy pandas seaborn ipython psutil thop tensorboard PyYAML PyQt5 protobuf==4.21.2 opencv-python pip install torch==1.10.0+cu113 torchvision==0.11.1+cu113 torchaudio===0.10.0+cu113 -f https://download.pytorch.org/whl/cu113/torch_stable.html
最高容許版本
pip install tqdm requests matplotlib scipy pandas seaborn ipython psutil thop tensorboard PyYAML PyQt5 protobuf opencv-python pip install torch==2.0.1+cu118 torchvision==0.15.2+cu118 torchaudio===2.0.2+cu118 -f https://download.pytorch.org/whl/cu118/torch_stable.html
最新的,不能用
pip install tqdm requests matplotlib scipy pandas seaborn ipython psutil thop tensorboard PyYAML PyQt5 protobuf==4.21.2 opencv-python
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
下載主程式
請先到 https://github.com/wongkinyiu/yolov7 下載主程式。解開後會有yolov7-main 這個目錄,然後把 yolov7-main 底下的所有目錄及檔案 copy 到 專案之下。
下載權重
同上述網址往下拉,會看到 yolov7.pt ,下載後置於 yolov7-main 目錄中
偵測圖片
請於 pycharm 專案中進入 terminal ,然後下達
python detect.py --weights yolov7.pt --conf 0.25 --img-size 1920 --view-img --source E:\ai\3.jpg
偵測完,會把結果儲存於 runs\detect\exp1 目錄中。加入 –view-img,是為了顯示偵測的結果,不過顯示圖片後,1ms就會退出。要想停留,還需修改程式碼,後續會說明。
偵測影片
若要偵測影片,如同上述指令,只需於 –source 參數後面加入影片檔名即可。
python detect.py --weights yolov7.pt --conf 0.25 --img-size 1920 --source E:\ai\2.mp4
結果亦置於 runs\detect\exp目錄中
使用 Python 偵測圖片
底下代碼,可以自行撰寫 Python 程式,偵測想要測試的圖片。
首先修改 detect.py 檔如下
def detect(save_img=False, myopt=None):
global opt
if myopt is not None: opt=myopt source, weights, view_img, save_txt, imgsz, trace = opt.source, opt.weights,
opt.view_img, opt.save_txt, opt.img_size, not opt.no_trace save_img = not opt.nosave and not source.endswith('.txt') # save inference images .................. print(f'Done. ({time.time() - t0:.3f}s)') return im0
然後請在專案中新增 “偵測圖片.py” 檔。此代碼故意把 opt.view_img 設為 False,因為預設是使用 opencv 顯圖。我們在此將傳回的圖片,使用 matplotlib 顯示。不過 yolov7 預設把 matplotlib 設為 agg 模式,是無法顯圖的,所以在偵測完後,需把 matplotlib 設為 qt5agg 模式。
import argparse import pylab as plt import matplotlib import cv2 import torch from detect import detect parser = argparse.ArgumentParser() opt = parser.parse_args() opt.weights='yolov7.pt' opt.img_size=1920 opt.source = "E:/ai/yolo4_1/images/766209.jpg" opt.view_img=False opt.save_txt=False opt.save_conf=False opt.classes=None#None才會標示框線 opt.no_trace=False opt.nosave=False#要儲存,才會畫框線 opt.project='runs/detect' opt.name='exp' opt.exist_ok=True #True才不會一直新增目錄 opt.device='0'#使用GPU 0裝置 opt.augment=False opt.conf_thres=0.25 opt.iou_thres=0.45 opt.agnostic_nms=False opt.update=False
with torch.no_grad(): img=detect(myopt=opt) img=cv2.cvtColor(img, cv2.COLOR_BGR2RGB) matplotlib.use('qt5agg') #需於偵測完,才能更改模式 plt.imshow(img) plt.axis("off") plt.show()

更改字体大小
字体大小,位於 utils/plots.py,如下藍色所示
def plot_one_box(x, img, color=None, label=None, line_thickness=3):
# Plots one bounding box on image img
tl = line_thickness or round(0.002 * (img.shape[0] + img.shape[1]) / 2) + 1 # line/font thickness
color = color or [random.randint(0, 255) for _ in range(3)]
c1, c2 = (int(x[0]), int(x[1])), (int(x[2]), int(x[3]))
cv2.rectangle(img, c1, c2, color, thickness=tl, lineType=cv2.LINE_AA)
if label:
tf = max(tl - 1, 1) # font thickness
t_size = cv2.getTextSize(label, 0, fontScale=tl / 0.8, thickness=tf)[0]
c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3
cv2.rectangle(img, c1, c2, color, -1, cv2.LINE_AA) # filled
cv2.putText(img, label, (c1[0], c1[1] - 2), 0, tl / 0.8, [225, 255, 255], thickness=tf, lineType=cv2.LINE_AA)
自定COCO模型
自定模型,是為了要測試 yolov7 是否真的能達到我們的需求,如果真的可以,那就可以大膽的浪費時間去收集我們自已專案所需的圖片。
COCO 資料,是官網幫我們準備好的圖片及 label,用來驗証他們的演算法是真實可用的,也不需浪費我們的時間去收集圖片跟標識。請先到 https://github.com/wongkinyiu/yolov7 下載 yolov7 原始碼,解壓縮至此後,會產生 yolov7-main,此為整個專案的根目錄。
安裝套件
pip install setuptools==59.5.0
下載 COCO 資料
在上面的網址往下拉,可以看到 train, val, test, labels 的下載網址,分別如下。
train : http://images.cocodataset.org/zips/train2017.zip
val : http://images.cocodataset.org/zips/val2017.zip
test : http://images.cocodataset.org/zips/test2017.zip
labels : https://github.com/WongKinYiu/yolov7/releases/download/v0.1/coco2017labels-segments.zip
test2017.zip 有 6G, train2017.zip 有 18G, 請耐心等待。下載後將上述 4 個檔 copy 到 yolov7-main 根目錄之下
1. coco2017labels-segments.zip 解壓縮至此,就會產生 coco目錄,裏面會有 labels 目錄。
2. val2017.zip 解壓縮至此,就會產生 val2017 目錄,將之移到 coco\images 之下。
3. test2017.zip 解壓縮至此,就會產生 test2017 目錄,將之移到 coco\images 之下。
4. train2017.zip 解壓縮至此,就會產生 train2017 目錄,將之移到 coco\images 之下。
train_2017 是訓練所需的圖片,共有 118,000 多張圖。
val_2017 是訓練時驗証所需的圖片,裏面有 5,000 張圖。
labels 是所有圖片標識後的資料,包含了類別及座標。
test_2017 是訓練後要評估分數用的,訓練時不會用到,裏面有 40,670 張圖。
整個目錄結構如下
yolov7-main ├─ venv #虛擬環境設定 ├─ cfg
│ ├─ baseline
│ ├─ deploy
│ ├─ training
│ │ ├─ yolov7.ymal
├─ coco │ ├─ images │ │ ├─ test2017 │ │ ├─ train2017
│ │ ├─ val2017 │ ├─ labels
│ │ ├─ train2017
│ │ ├─ val2017
├─ data │ ├─ coco.yaml
│ ├─ hyp.scratch.p5.paml
│ ├─ hyp.scratch.p6.paml ├─ detect.py
├─ train.py ├─ test.py
訓練 COCO 模型
使用底下指令開始進行訓練,訓練的 epoch 預設為300次,每次訓練的時間約1小時,所以總訓練時間會長達10天左右。
可由以下連結下載本人已訓練好的模型 : coco_best.pt
python train.py --epoch 300 --workers 8 --device 0 --batch-size 8 --data data/coco.yaml --img 640 640 --cfg cfg/training/yolov7.yaml --name yolov7 --hyp data/hyp.scratch.p5.yaml --weights ''
--workers 是要動用的CPU數量,因為大部份的計算會交由 GPU,所以這參數沒啥影響。
--epochs 是指要迭代的次數,如果沒有這個參數,預設是 300 次。次數愈大可能愈精準,但也可能會造成過度擬合而浪費訓練時間,所以就按預設的 300 次即可。
--batch-size 是每一次能處理的數量。每次能處理的數量愈大,速度當然就愈快。
所以 --batch-size 的值愈大速度愈快,值愈小速度愈慢。
nVidia 3080Ti 12G 的顯卡,--batch-size 可以調到 8。
顯卡記憶体若少於 12G, --batch-size 只能調為 4
顯卡記憶体如果只有 4G,根本無法執行。
Google 的 Colab 也只能調到 4
(Colab 是要錢的,而且收費像在搶銀行。所以不如平日省點花,買個好一點的顯卡)
第一次訓練,會讀取 train 及 val 二個目錄中的圖片,然後在 coco 目錄下產生 train2017.cache 及 val2017.cache 二個檔,train2017 目錄裏面有 11 多萬張圖,如果使用一般傳統硬碟的話,會讀蠻久的。產生這二個檔後,如果訓練中途中斷再重新訓練,就直接由這二個 cache 檔讀取要訓練的資料。
–weights 若沒有加入,則會使用預設的 yolov7.pt 權重。所以開始訓練時一定要加入 –weights ” ,表示要使用空白權重。COCO 訓練約需300小時,若中途中斷訓練,只需設定 –weights 就可以從中間開始訓練。參數設定如下,注意喔,不可以使用 ”
--weights ./runs/train/yolov7/weights/best.pt
比如如下所示
python train.py --workers 8 --device 0 --batch-size 8 --data data/coco.yaml --img 640 640 --cfg cfg/training/yolov7.yaml --name yolov7 --hyp data/hyp.scratch.p5.yaml --weights ./runs/train/yolov7/weights/last.pt
300 小時,約 12 天半,快半個月,若以 3080Ti 顯卡的功率來說,這半個月的電費可能會多出
400W * 24hrs / 1000 * 5元/度 = NT$720 元,請先作好心理準備。
錯誤
如果出現If this call came from a _pb2.py file, your generated code is out of date and must be regenerated with protoc >= 3.19.0. ,請使用如下指令將 protobuf 降到 3.20.1版本
pip3 install --upgrade protobuf==3.20.1
監控
在另一個DOS命令視窗輸入如下
tensorboard --logdir runs/train
然後開啟瀏覽器,網址 http://localhost:6006即可看到目前訓練狀況
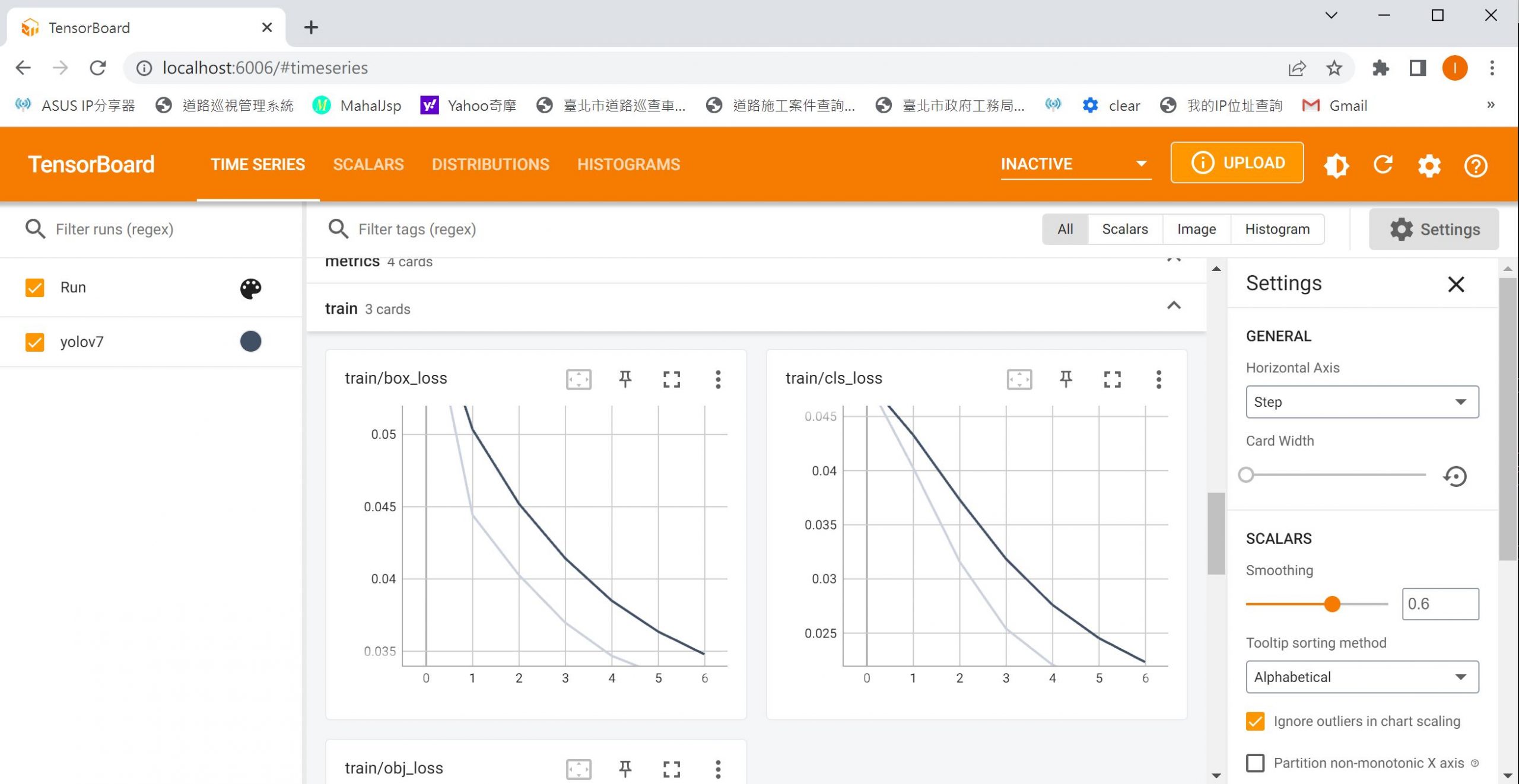
輸出
訓練完成後,會在專案下自動新增 runs 目錄,裏面還會有 detect 及 train 二個目錄。train 為訓練後權重存放位置,detect 為辨識後結果存放位置。
目錄結構如下藍色
yolov7-main
├─ venv #虛擬環境設定
├─ cfg │ ├─ baseline │ ├─ deploy │ ├─ training │ │ ├─ yolov7.ymal ├─ coco
│ ├─ images
│ │ ├─ test2017
│ │ ├─ train2017 │ │ ├─ val2017
│ ├─ labels │ │ ├─ train2017 │ │ ├─ val2017 ├─ data
│ ├─ coco.yaml │ ├─ hyp.scratch.p5.paml │ ├─ hyp.scratch.p6.paml
├─ runs
│ ├─ detect (辨識後的結果)
│ ├─ train (訓練後的權重)
辨識新圖片
detect.py 可辨識新圖片,後面的 weights 參數指定我們自已訓練好的權重 “best.pt” , source 參數指定要辨識的圖片即可。
python detect.py --weights ./runs/train/yolov7/weights/best.pt --conf 0.3 --source ./fruits/images/guava_0018.jpg
訓練自已的模型
訓練資料
底下的下載網址,是本篇訓練的圖片資料及訓練好的模型,下載完後,置於專案之下即可。
圖片資料 : fruits.zip
訓練好的模型 : runs.zip
目錄結構如下
yolov7-main
├─ venv #虛擬環境設定
├─ fruits
│ ├─ images
│ ├─ labels
│ ├─ train.txt
│ ├─ val.txt
├─ runs
│ ├─ train
收集圖片
收集圖片是個龐大的工程,要收集的圖片都是上萬張以上,每張圖的解析度盡可能的大,這樣才能清楚看出上面的紋理、形狀、顏色及其它特徵。另外最好有多物件同在一張圖,背景複雜沒關係,只要人眼可以分辨出來就好。
本例以水果為例,共有四種,分別為guava、 lemon、pitaya、wax。所以在專案下,新增 fruits目錄,裏面有images及labels二個目錄。images下又區分為 guava/ lemon/pitaya/wax,所以 labels底下也需有 guava、 lemon、pitaya及wax。
也就是說 images 下有什麼目錄,那麼 labels 下也要跟隨同樣的目錄。
yolov7-main ├─ venv #虛擬環境設定 ├─ cfg
│ ├─ baseline
│ ├─ deploy
│ ├─ training
│ │ ├─ yolov7.ymal
├─ fruits │ ├─ images │ │ ├─ guava
│ │ │ ├─ .....jpg
│ │ ├─ lemon
│ │ │ ├─ .....jpg
│ │ ├─ pitaya
│ │ │ ├─ .....jpg
│ │ ├─ wax
│ │ │ ├─ .....jpg
│ ├─ labels
│ │ ├─ guava
│ │ │ ├─ .....txt
│ │ ├─ lemon
│ │ │ ├─ .....txt
│ │ ├─ pitaya
│ │ │ ├─ .....txt
│ │ ├─ wax
│ │ │ ├─ .....txt
│ ├─ train.txt
│ ├─ val.txt
標識圖片
使用 LabelImg 標識每個物件的種類。如果人眼不確定或是分辨不出來的物件就不要標識。因為人都辨識不出來的東西,電腦也無法辨識,請不要把電腦當作神。
請在命令提示字元視窗輸入 pip install labelimg,然後直接執行 labelimg 即可開始標識圖片。
圖片列表
請使如下代碼,於fruits目錄下產生 train.txt 及 val.txt。此程式依不同的水果,將 90% 的檔案列為train.txt, 10% 的檔案列為 val.txt。
import os
import random
imgs_path="fruits/images"
fruits=os.listdir(imgs_path)
train=open("fruits/train.txt", "w")
val=open("fruits/val.txt","w")
for fruit in fruits:
files=os.listdir(os.path.join(imgs_path, fruit))
ls=[f'./images/{fruit}/{file}' for file in files]
random.shuffle(ls)
total=len(ls)
for i, f in enumerate(ls):
if i<total*0.9:
train.write(f'{f}\n')
else:
val.write(f'{f}\n')
train.close()
val.close()
cfg設定檔
copy cfg/training/yolov7.yaml,並改名為 fruits.yaml,然後將 nc 改為 4
# parameters
nc: 4 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
# anchors
anchors:
- [12,16, 19,36, 40,28] # P3/8
- [36,75, 76,55, 72,146] # P4/16
.....................
data
在 /data 目錄下新增 fruits.yaml,撰寫如下設定
download: bash ./scripts/get_coco.sh train: ./fruits/train.txt val: ./fruits/val.txt test: ./fruits/test.txt nc: 4 names: [ 'guava', 'lemon', 'pitaya', 'wax' ]
訓練
請於DOS命令模式輸入如下指令開始執行訓練。因為我們的圖片不多,所以加了 –epochs 3000,讓訓練的次數多達 3000次,損失率可以慢慢的下降。
經測試,epochs 調到 2000 次,芭樂會看蓮霧。但調到 3000 次,則會準到讓人嚇死,只不過要花個 1.5 小時 ~ 2 小時。
python train.py --workers 8 --device 0 --batch-size 8 --data data/fruits.yaml --img 640 640 --cfg cfg/training/fruits.yaml --weights '' --name yolov7 --hyp data/hyp.scratch.p5.yaml --epochs 3000
辨識圖片
上述沒有外接顯卡的人是無法訓練模型的,請由如下網址下載 runs.zip,解開後置於專案之下即可 :
runs.zip
然後下達如下指令
python detect.py --weights ./runs/train/yolov7/weights/best.pt --conf 0.1 --source ./fruits/images/pitaya/31_cn1.jpg
或者使用下面代碼
import argparse
import pylab as plt
import matplotlib
import cv2
import torch
from detect import detect
parser = argparse.ArgumentParser()
opt = parser.parse_args()
opt.weights='runs/train/yolov7/weights/best.pt'
opt.img_size=640
#opt.source = "./fruits/images/guava/guava_0001.jpg"
opt.view_img=False
opt.save_txt=False
opt.save_conf=False
opt.classes=None#None才會標示框線
opt.no_trace=False
opt.nosave=False#要儲存,才會畫框線
opt.project='runs/detect'
opt.name='exp'
opt.exist_ok=True #True才不會一直新增目錄
opt.device='0'#使用GPU 0裝置
opt.augment=False
# opt.conf_thres=0.25
# opt.iou_thres=0.45
opt.conf_thres=0.1
opt.iou_thres=0.60
opt.agnostic_nms=False
opt.update=False
#opt.source = "./fruits/images/guava/guava_0003.jpg"
#opt.source = "./fruits/images/pitaya/5710_CKBDTG_d4xepni.jpg"
path="fruits/images/wax"
matplotlib.use('qt5agg')
with torch.no_grad():
for file in os.listdir(path):
opt.source=os.path.join(path, file)
img=detect(myopt=opt)
img=cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
plt.imshow(img)
plt.axis("off")
plt.show()

小插曲
本人原本只使用 guava 及 lemon 二種水果進行測試,但怎麼訓練都不準,後來加入火龍果 pitaya 及 蓮霧 wax 共四種水果後,就準的不要不要的。看來還是要準備多一點的圖片,而且最好是紋路特別鮮明的比較好訓練。